AcroForm vs PDF plat : rendre n'importe quel formulaire remplissable en 2026
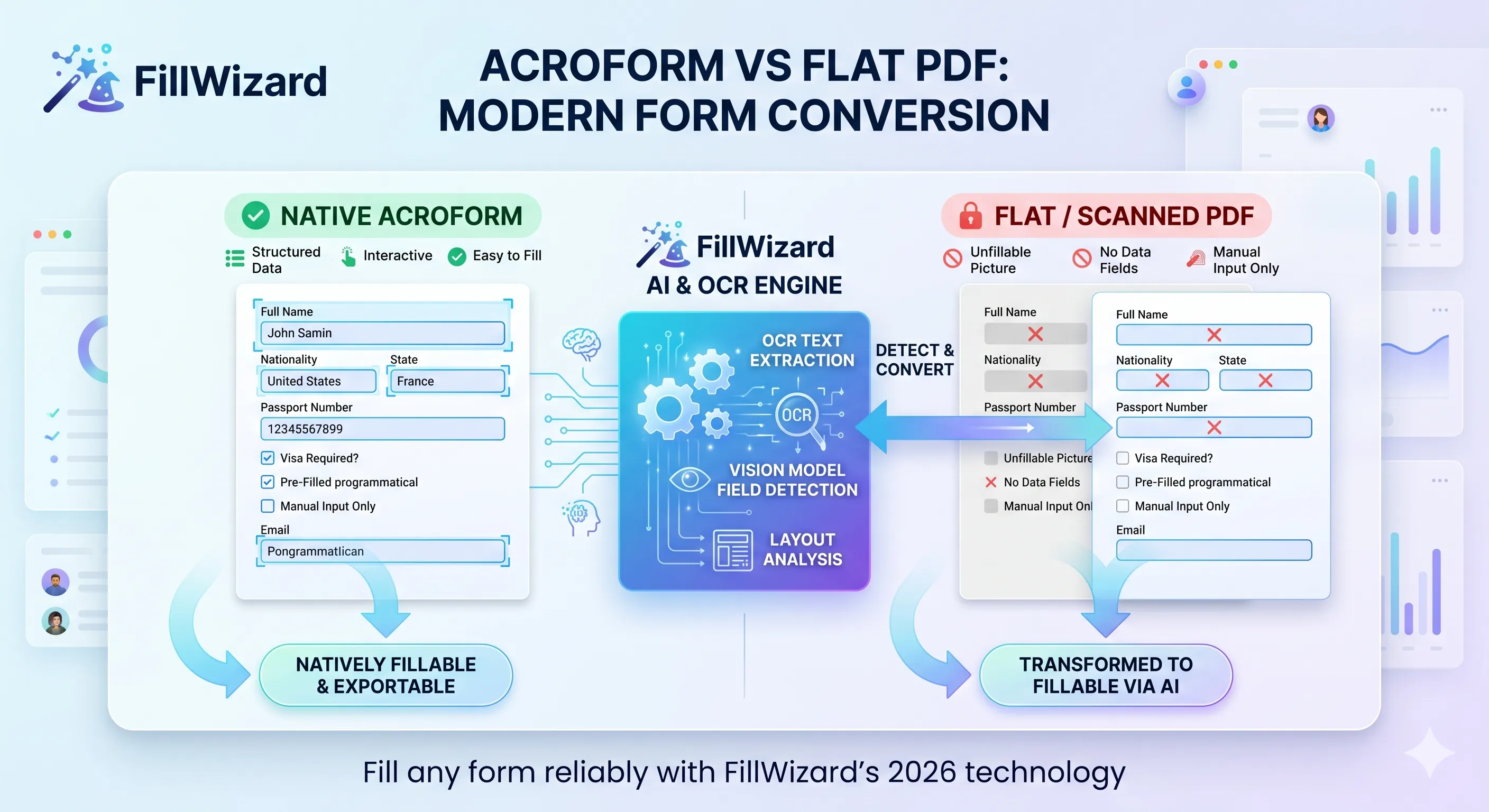
Si tu as déjà ouvert deux PDF visuellement identiques et qu'un seul accepte la frappe, tu connais déjà la coupure la plus fondamentale de l'écosystème PDF. Les deux ressemblent à des formulaires. Un seul est un formulaire au sens technique. L'autre est une photo de formulaire.
Comprendre cette différence est le socle de tout workflow moderne d'autoremplissage. Les outils qui les traitent à l'identique produisent des sorties cassées. Ceux qui voient la différence remplissent les deux de façon fiable. Cet article montre ce qui se passe sous le capot, pourquoi certains PDF résistent à l'automatisation, et comment l'outillage 2026 comble l'écart.
C'est l'article le plus technique de la série, mais nul besoin d'être ingénieur pour suivre. Si tu as déjà tapé <input> en HTML, les concepts seront familiers.
Les quatre types de PDF qui ressemblent à des formulaires
La plupart pensent qu'« PDF remplissable » est une seule catégorie. Il y en a quatre :
1. AcroForm
Introduit dans PDF 1.2 (1996), AcroForm est la techno dominante des formulaires remplissables. Le PDF embarque des objets de champ (entrées /Annot de sous-type /Widget plus un dictionnaire /AcroForm au niveau document). Chaque champ a :
- Un nom (par exemple
passport_number) - Un type (texte, bouton/case, radio, choix, signature)
- Une position sur la page (rectangle en coordonnées PDF)
- Valeur par défaut optionnelle, validation, actions JavaScript
Les champs AcroForm sont interrogeables. Tu ouvres le PDF par programmation et tu peux lister chaque champ, son nom, son type et sa valeur. C'est le sens précis de « PDF remplissable ».
2. XFA (XML Forms Architecture)
Introduit dans PDF 1.5 (2003), XFA emballe une définition de formulaire en XML dans un conteneur PDF. La tentative d'Adobe d'amener un comportement plus riche (champs dynamiques, validation complexe, sections conditionnelles) dans les PDF. Ne marche qu'avec Adobe Reader sur les plateformes prises en charge.
XFA a été déprécié dans PDF 2.0 (2017). On le retrouve dans des formulaires anciens, gouvernementaux ou d'entreprise. Si tu as déjà ouvert un formulaire fiscal dans Chrome PDF Viewer et vu « Veuillez ouvrir avec Adobe Reader », tu as croisé du XFA.
Pour l'automatisation moderne, traite XFA comme un PDF plat : rendu, OCR, remplissage. Manipuler le XML directement est fragile et rarement payant.
3. Hybride (AcroForm + XFA)
Certains PDF contiennent les deux représentations du même formulaire. Pour la rétrocompatibilité : Adobe Reader utilise XFA, le reste retombe sur AcroForm. Les hybrides sont de plus en plus rares mais existent dans des formulaires financiers et publics produits avant 2018.
Pour automatiser : lis le côté AcroForm, ignore le XFA, remplis les champs AcroForm, aplatis à l'export.
4. Plat / scanné
Un PDF plat n'a aucune structure remplissable. C'est une suite de pages rendues (texte, images, formes vectorielles) sans notion de champ. Les « cases » que voit l'utilisateur sont des éléments visuels, pas des données.
Deux façons de produire un PDF plat :
- Plat d'origine : un graphiste a dessiné le formulaire dans InDesign, exporté en PDF, sans jamais ajouter de champ AcroForm. Les cases sont des rectangles. Les libellés sont du texte.
- Scanné : un formulaire papier a été photocopié et enregistré en PDF. Toute la page est en gros une image. Même les libellés sont des pixels.
Ce sont les PDF qui « refusent la frappe ». Et ceux que les outils anciens ne savent pas gérer, parce qu'il n'y a rien à interroger. Que des pixels.
Pourquoi cette distinction compte au quotidien
Pour une équipe qui traite des milliers de formulaires sur plusieurs workflows, la coupure AcroForm/plat a des conséquences concrètes :
Les AcroForm s'automatisent 10 fois plus facilement. Tu listes les champs, tu les mappes au profil, tu écris les valeurs, tu aplatis. Quelques millisecondes.
Les plats demandent de la détection. Il faut trouver les champs visuellement (boîtes englobantes) avant de pouvoir remplir. C'est là où l'OCR et les modèles de vision modernes gagnent leur place.
Les paquets mixtes cassent les workflows naïfs. Un dossier de visa, une réponse RFP ou un dossier de sinistre réel mêle régulièrement AcroForm et plats. Un workflow qui n'en gère qu'un force du manuel sur l'autre moitié.
La gestion des signatures change beaucoup. Les champs de signature AcroForm se remplissent par programme. Les lignes de signature en PDF plat doivent être superposées. Une signature ratée invalide le formulaire.
Comment les outils modernes détectent les champs en PDF plat
Si les AcroForm se lisent directement, l'ingénierie intéressante est sur les plats. Le pipeline 2026 ressemble à ça :
Étape 1 : rendre la page
Le PDF plat est rendu en image haute résolution (généralement 300 DPI ou plus). PDF.js, Poppler ou Ghostscript le font de façon fiable.
Étape 2 : OCR
Le texte est extrait avec ses positions. Les moteurs OCR modernes (Tesseract 5, Google Document AI, Microsoft Azure Form Recognizer ou modèles open-source comme Donut et LayoutLM) produisent une liste de paires (texte, boîte).
Étape 3 : analyse de mise en page
Un modèle de layout repère les régions structurelles : paragraphes, tableaux, en-têtes, zones remplissables. Le modèle sait à quoi ressemble un formulaire : lignes vides à côté d'un texte, cases dessinées en petits carrés vides, lignes de signature avec « Signature » dessous.
Étape 4 : association de champs
Chaque zone remplissable est associée à l'étiquette la plus proche. « Numéro de passeport » à côté d'une ligne signifie que la ligne est le champ passeport. Les modèles vision-langage brillent ici : ils distinguent « Date d'émission » de « Date d'expiration » même dans un layout serré.
Étape 5 : classification du type
Chaque champ détecté est classé en texte, case, signature ou date. Cela pilote la suite : les champs texte reçoivent les valeurs du profil, les cases sont cochées, les signatures sont signalées pour action humaine.
La sortie de ce pipeline ressemble à ce que produirait un AcroForm natif. À partir de là, le reste du workflow est identique.
Pour vue d'ensemble dans un moteur complet, vois notre guide définitif d'autoremplissage par IA.
Pourquoi les anciens outils échouent en PDF plat
La génération précédente de tools (milieu des années 2010) tentait de résoudre le plat par template-matching. L'utilisateur :
- Téléversait un PDF d'exemple.
- Cliquait manuellement sur chaque emplacement de champ pour dessiner une boîte.
- Étiquetait chaque boîte avec un nom de champ.
- Sauvegardait le gabarit.
À l'arrivée du PDF suivant avec la même mise en page, l'outil projetait le gabarit et remplissait.
En théorie, ça marche. En pratique, ça casse pour trois raisons :
- Dérive de gabarit : un logo nouveau, un avis déplacé, et l'alignement disparaît.
- Coût par formulaire : un dossier RFP de 40 formulaires, ce sont 40 gabarits, chacun 5-10 minutes de mise en place.
- Pas de transfert sémantique : un gabarit connaît des positions, pas du sens. Un champ « Last Name » chez un assureur et « Surname » chez un autre demandent deux gabarits.
Les pipelines de détection modernes contournent les trois. Ils détectent à neuf à chaque fois, étiquettent par sémantique, et ne demandent aucun setup par formulaire.
Remplir sans casser l'original
Une fois les champs détectés, le remplissage doit être chirurgical. Deux modes d'échec à éviter :
Échec 1 : modifier le contenu de la page. Si tu écrases les valeurs du profil dans le flux de page, tu casses des choses. Les polices embarquées disparaissent. Les signatures existantes s'invalident. Les métadonnées se déforment. Certains lecteurs refusent de rendre.
Échec 2 : sauvegarder un PDF non aplati comme livrable final. Si tu remplis un AcroForm et sauvegardes sans aplatir, le destinataire peut éditer les valeurs. Pour des envois critiques (visa, public, juridique), c'est inacceptable.
La bonne approche dans les deux cas :
- PDF AcroForm : écris les valeurs dans les objets de champ existants, puis aplatis à l'export. Résultat : un PDF propre et immuable, identique dans tous les lecteurs.
- PDF plat : rends la page, superpose les valeurs aux positions détectées sur une couche transparente, aplatis le tout. Les signatures existantes (présentes dans le contenu) survivent. Les nouvelles valeurs deviennent partie intégrante de la page.
Un bon outil d'autoremplissage gère les deux automatiquement, en choisissant l'approche selon le type d'entrée.
Quand l'OCR ne te sauvera pas, honnêtement
L'OCR a des limites. La liste honnête des cas où l'automatisation cale :
- Photos de téléphone de travers : la distorsion trapézoïdale embrouille le modèle. Demande un scan à plat ou une app doc-scanner.
- Fax : la dynamique est brutale. Réimprime et rescanne si possible.
- Étiquettes manuscrites : rare en formulaires modernes, présent en formulaires publics anciens. Étiquetage manuel inévitable.
- Formulaires aux symboles non standards : notation type échecs, équations, codes propres à une institution. Demandent un entraînement custom, pas de l'OCR de série.
- Mises en page denses multi-colonnes sans séparation : les modèles de layout galèrent. Quelques ajustements requis.
Les 90 % restants des formulaires réels marchent proprement. Connaître les modes d'échec évite de promettre trop pendant un PoC.
Aspects multilingues
Pour les équipes qui traitent des formulaires non anglais (la majorité de nos lecteurs ; vois nos workflows sinistre, appel d'offres public et dossier de visa), la langue impacte l'étape OCR :
- Scripts latins (anglais, espagnol, français, allemand, portugais) : pris en charge par tout OCR moderne.
- Scripts RTL (arabe, hébreu) : moteurs OCR spécifiquement entraînés sur du RTL. L'ordre des mots et la direction des champs changent.
- Asie de l'Est (chinois, japonais, coréen) : moteurs avec données d'entraînement adéquates et DPI plus élevé.
- Formulaires multi-scripts : très courants en visa (instructions anglaises + champ nom en arabe). Un moteur capable des deux dans la même passe économise une étape.
Les libellés de champ dans la langue source ont besoin d'un mappage sémantique vers tes champs profil. Un champ Nationalité doit mapper à Nationality dans le profil. Le mappage sémantique moderne le fait de façon transparente ; les anciens outils exigeaient un dictionnaire de traduction.
L'étape d'export dont personne ne parle
Un PDF correctement rempli mais qui rend mal chez le destinataire est fonctionnellement un échec d'envoi. Après remplissage et aplatissement, valide dans :
- Adobe Acrobat (renderer canonique de référence)
- macOS Preview (moteur différent, met à jour les soucis de polices)
- Visionneuse PDF de Chrome (plus petit dénominateur commun pour ambassades et agences)
- Pilote d'imprimante (certaines signatures ne s'affichent qu'à l'impression)
Si la sortie rend proprement dans les quatre, tu as un PDF prêt à être envoyé. Sinon, corrige avant d'envoyer. Ne suppose jamais que le destinataire utilise le même lecteur que toi.
Arbre de décision pratique
Quand un nouveau PDF arrive, l'arbre est :
- C'est un AcroForm ? → Lis les champs directement. Remplis. Aplatis. Fini.
- C'est du XFA ? → Rends en image. Traite comme PDF plat.
- C'est un hybride ? → Lis le côté AcroForm. Remplis. Aplatis. Fini.
- C'est plat ou scanné ? → OCR + détection layout. Mappe les champs. Superpose les valeurs. Aplatis.
Un outil moderne fait cet arbre tout seul. Tu téléverses, il décide quel type de PDF, il route vers le bon pipeline. Côté utilisateur, c'est un seul workflow.
À lire ensuite
- Le guide définitif du remplissage PDF par IA 2026 : comment ces briques s'assemblent en bout-en-bout.
- Workflow de déclaration de sinistre : les mêmes fondations dans une verticale concrète.
- Remplissage de formulaires publics : mêmes fondations, marchés publics.
- FillWizard vs Adobe Acrobat vs DocuSign : comparaison directe, gestion AcroForm/plat des trois outils.
Quoi faire cette semaine
Si ton équipe traite un mélange d'AcroForm et de PDF plats et n'automatise qu'un des deux, tu laisses 50 % du gain de temps sur la table. Choisis trois PDF plats de ta charge réelle, passe-les dans un outil moderne avec détection visuelle de champs, et mesure la sortie. L'écart entre « gère mal les plats » et « gère bien les plats » est exactement l'écart entre l'outillage d'hier et celui d'aujourd'hui.
Liste de contrôle
- Identifie pour chaque PDF entrant s'il est AcroForm, XFA, hybride ou plat/scanné.
- Pour les AcroForm : lis directement noms, types et structure des champs, sans OCR.
- Pour les PDF plats : lance l'OCR avec un modèle de mise en page qui détecte les boîtes englobantes.
- Utilise un mappage sémantique pour projeter les valeurs du profil sur les champs détectés.
- Préserve les signatures originales en superposant les valeurs plutôt qu'en recréant le document.
- Exporte vers un PDF aplati qui s'ouvre correctement dans tous les lecteurs.
- Vérifie la sortie dans Acrobat, Preview et un pilote d'imprimante avant l'envoi.
Articles liés
 Multilingual Workflows
Multilingual WorkflowsFormulaires en arabe avec l'IA : noms en double graphie, dates hégiriennes et RTL qui fonctionnent vraiment
La plupart des outils traduisent l'étiquette et s'arrêtent là. Le vrai travail sur les formulaires arabes demande la double graphie, les dates hégiriennes et une couche de relecture qui coule du bon côté.
9 min de lectureLire la suite Workflows de visa
Workflows de visaComment l'IA remplit le formulaire de visa DS-160 en 4 minutes (et ce qu'elle ne peut pas faire)
Le DS-160 prend 90 minutes la première fois et 60 la deuxième. L'IA en remplit l'essentiel en quatre minutes. L'entretien reste entre vous et l'agent consulaire.
8 min de lectureLire la suite Workflows fiscaux
Workflows fiscauxDéclaration d'impôts allemande avec l'IA : guide pratique d'Elster, Anlage N, KAP et S
Elster est obligatoire pour la plupart des déclarations, mais l'interface est rude. Voici comment Anlage N, KAP et S marchent en vrai, et comment l'IA les pré-remplit à partir de vos justificatifs et bulletins avant l'envoi par Elster.
8 min de lectureLire la suite