AcroForm vs PDF plano: cómo hacer rellenable cualquier formulario en 2026
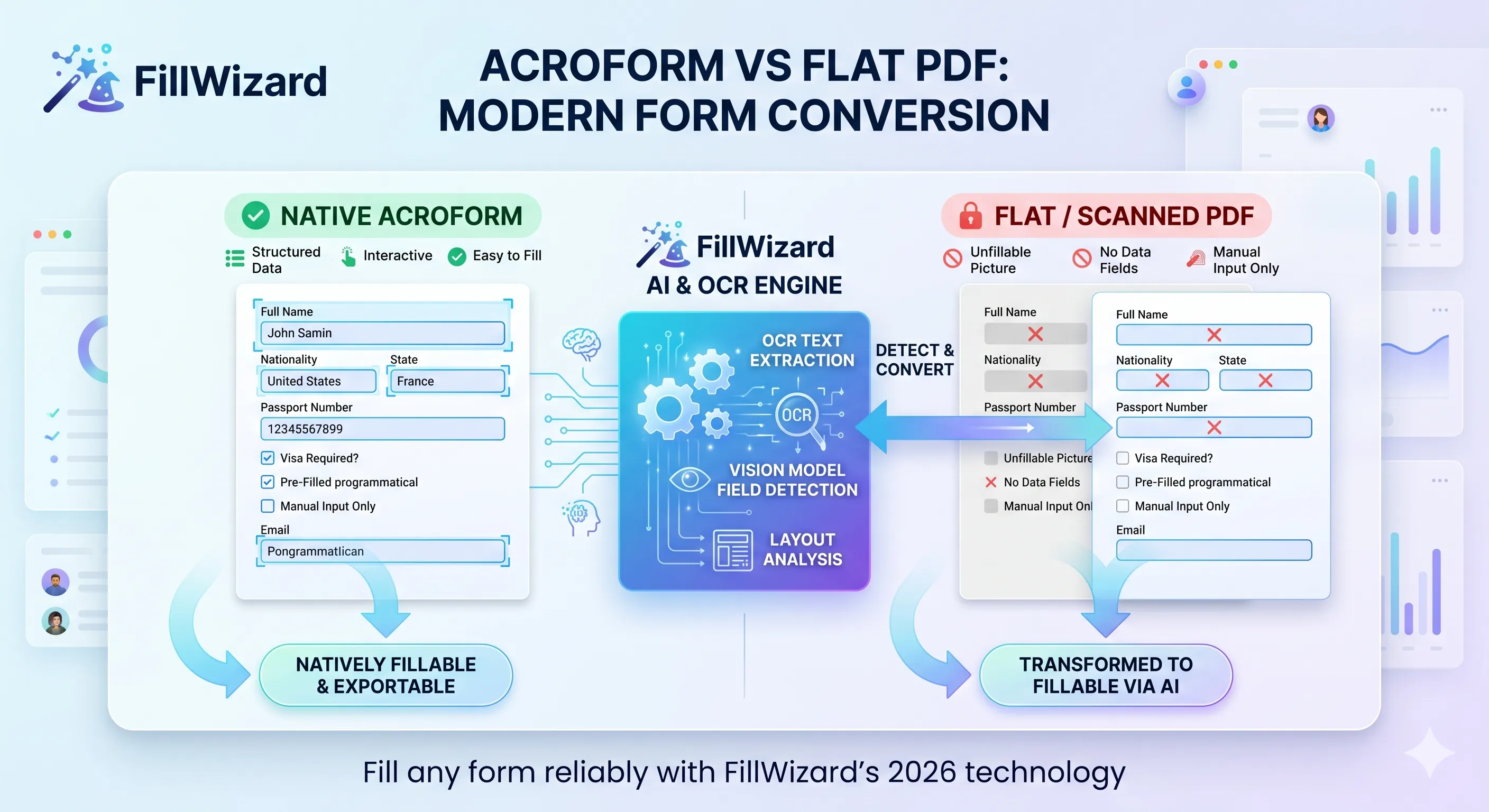
Si alguna vez has abierto dos PDF visualmente idénticos y has visto que en uno se puede teclear y en el otro no, ya conoces la división más profunda del ecosistema PDF. Los dos parecen formularios. Solo uno es un formulario en cualquier sentido técnico. El otro es una foto de un formulario.
Entender esa diferencia es la base de cualquier flujo moderno de autorrelleno PDF. Las herramientas que tratan ambos por igual producen salidas rotas. Las que reconocen la diferencia rellenan ambos con fiabilidad. Este artículo recorre lo que pasa por debajo, por qué algunos PDF resisten cabezotamente la automatización y cómo las herramientas de 2026 cierran la brecha.
Es el artículo más técnico de la serie, pero no necesitas ser ingeniero para seguirlo. Si alguna vez has escrito <input> en HTML, los conceptos te resultarán familiares.
Los cuatro tipos de PDF que parecen formularios
La mayoría piensa en "PDF rellenable" como una sola categoría. En realidad hay cuatro:
1. AcroForm
Introducido en PDF 1.2 (1996), AcroForm es la tecnología dominante de formularios rellenables. El PDF incrusta objetos de campo (entradas /Annot con subtipo /Widget, más un diccionario /AcroForm a nivel de documento). Cada campo tiene:
- Un nombre (por ejemplo,
passport_number) - Un tipo (texto, botón/casilla, radio, elección, firma)
- Una posición en la página (rectángulo en coordenadas PDF)
- Valor por defecto opcional, validación y acciones JavaScript
Los campos AcroForm son consultables. Abres el PDF programáticamente y puedes listar cada campo, su nombre, su tipo y su valor actual. Eso es lo que significa "PDF rellenable" cuando se usa el término con precisión.
2. XFA (XML Forms Architecture)
Introducido en PDF 1.5 (2003), XFA envuelve una definición de formulario en XML dentro de un contenedor PDF. Era el intento de Adobe de meter comportamiento más rico (campos dinámicos, validación compleja, secciones condicionales) en los PDF. Solo funciona en Adobe Reader sobre plataformas soportadas.
XFA quedó obsoleto en PDF 2.0 (2017). Sigue siendo común en formularios antiguos de gobierno y empresa. Si alguna vez has intentado abrir un formulario fiscal en el visor PDF de Chrome y has visto "Por favor, abra en Adobe Reader", te has topado con XFA.
Para automatizar, lo mejor es tratar XFA como PDF plano: renderizarlo, hacer OCR y rellenarlo. Manipular el XML directamente es frágil y rara vez vale la pena.
3. Híbrido (AcroForm + XFA)
Algunos PDF incluyen una representación AcroForm y otra XFA del mismo formulario. Es por compatibilidad: Adobe Reader usa XFA, todo lo demás cae a AcroForm. Los híbridos son cada vez más raros, pero te los encontrarás en formularios financieros y de gobierno producidos antes de 2018.
Para automatizar: lee el lado AcroForm, ignora el XFA, rellena los campos AcroForm, aplana al exportar.
4. Plano / escaneado
Un PDF plano no tiene estructura rellenable. Es una secuencia de páginas renderizadas (texto, imágenes, formas) sin concepto de campo. Las "cajas" que ve el usuario son elementos visuales, no datos.
Dos formas en que se producen los PDF planos:
- Plano original: un diseñador dibujó el formulario en InDesign, exportó a PDF y nunca añadió campos AcroForm. Las cajas son rectángulos. Las etiquetas son texto.
- Escaneado: un formulario en papel se fotocopió y se guardó como PDF. La página entera es básicamente una imagen. Hasta las etiquetas de texto son píxeles.
Estos son los PDF que "no te dejan teclear". También son los que las herramientas antiguas no pueden manejar, porque no hay nada que consultar. Solo píxeles.
Por qué importa esta distinción operativamente
Para un equipo que maneja miles de formularios entre flujos, el corte AcroForm/plano tiene consecuencias reales:
Los AcroForm se automatizan 10x más fácil. Listas campos, los mapeas a datos del perfil, escribes valores, aplanas. Todo el proceso lleva milisegundos.
Los planos requieren detección. Tienes que encontrar los campos visualmente (detección de cajas) antes de poder rellenar nada. Aquí es donde el OCR moderno y los modelos de visión se ganan su sitio.
Los paquetes mixtos rompen flujos ingenuos. Un dossier de visado real, una respuesta a RFP o un paquete de siniestro suele incluir AcroForm y planos. Un flujo que solo cubre uno fuerza intervención manual sobre la otra mitad.
El manejo de firmas cambia mucho. Los campos de firma AcroForm se pueden poblar programáticamente. Las líneas de firma en PDF planos hay que superponerlas. Firmas mal hechas invalidan formularios.
Cómo las herramientas modernas detectan campos en PDF planos
Si los AcroForm se leen directamente, la ingeniería interesante ocurre en los planos. El pipeline de detección de 2026 se ve así:
Paso 1: renderiza la página
El PDF plano se renderiza a una imagen de alta resolución (típicamente 300 DPI o más). PDF.js, Poppler o Ghostscript lo manejan con fiabilidad.
Paso 2: OCR
Se extrae texto con posiciones. Los motores OCR modernos (Tesseract 5, Google Document AI, Microsoft Azure Form Recognizer u open-source como Donut y LayoutLM) producen una lista de pares (texto, caja).
Paso 3: análisis de layout
Un modelo de layout identifica regiones estructurales: párrafos, tablas, encabezados, regiones rellenables. El modelo sabe qué aspecto tiene un formulario: líneas horizontales vacías junto a etiquetas, casillas dibujadas como pequeños cuadrados vacíos, líneas de firma con "Firma" debajo.
Paso 4: asociación de campos
Cada región rellenable se asocia con la etiqueta más cercana. "Número de pasaporte" pegado a una línea horizontal significa que la línea es el campo de pasaporte. Aquí es donde brillan los modelos de visión-lenguaje: pueden distinguir "Fecha de emisión" de "Fecha de caducidad" incluso con layouts apretados.
Paso 5: clasificación de tipo
Cada campo detectado se clasifica como texto, casilla, firma o fecha. Eso dirige el comportamiento aguas abajo: los de texto reciben valores del perfil, las casillas se marcan, las firmas se marcan para acción humana.
La salida de este pipeline es una estructura prácticamente idéntica a la que habría producido AcroForm de forma nativa. A partir de aquí, el resto del flujo es el mismo.
Para una vista de alto nivel de cómo encaja en un motor completo, mira nuestra guía definitiva del autorrelleno con IA.
Por qué las herramientas antiguas fallan en PDF planos
La generación anterior de herramientas PDF (mediados de los 2010) intentó resolver el problema con coincidencia de plantilla. El usuario:
- Subía un PDF de muestra.
- Hacía clic manualmente sobre cada campo para dibujar una caja.
- Etiquetaba cada caja con un nombre de campo.
- Guardaba la plantilla.
La siguiente vez que llegaba un PDF con la misma maqueta, la herramienta proyectaba la plantilla guardada y rellenaba.
Funciona en teoría. En la práctica se rompe por tres motivos:
- Drift de plantilla: cambios mínimos (un logo nuevo, un disclaimer movido) desalinean la plantilla.
- Coste de mano de obra por formulario: un dossier RFP de 40 formularios son 40 plantillas, cada una con 5-10 minutos de configuración.
- Sin transferencia semántica: una plantilla conoce posiciones, no significado. Un campo etiquetado "Apellido" en una aseguradora y "Surname" en otra exige plantillas separadas.
Los pipelines modernos de detección esquivan los tres problemas. Detectan campos frescos cada vez, los etiquetan semánticamente y no requieren configuración por formulario.
Rellenar sin romper el original
Una vez detectados los campos, el relleno tiene que ser quirúrgico. Los dos modos de fallo a evitar:
Fallo 1: editar el contenido de la página. Si aplastas valores del perfil sobre el flujo de página existente, rompes cosas. Las fuentes embebidas desaparecen. Las firmas existentes se invalidan. Los metadatos se mancillan. Algunos lectores PDF se niegan a renderizar el resultado.
Fallo 2: guardar un PDF sin aplanar como salida final. Si rellenas campos AcroForm y guardas sin aplanar, la parte receptora puede editar los valores. Para envíos críticos (visado, gobierno, legal), eso es inaceptable.
El enfoque correcto en ambos casos:
- PDF AcroForm: escribes valores en los objetos de campo existentes y aplanas al exportar. Resultado: un PDF limpio e inmutable que se ve igual en cualquier lector.
- PDF planos: renderizas la página, superpones los valores en las posiciones detectadas sobre una capa transparente y aplanas el resultado. Las firmas originales (que viven en el contenido de la página) sobreviven intactas. Los nuevos valores pasan a formar parte permanente de la página.
Una herramienta de autorrelleno bien hecha maneja ambos casos automáticamente y elige el enfoque según el tipo de PDF de entrada.
Cuándo el OCR honestamente no te va a salvar
El OCR tiene límites. La lista honesta de casos donde la automatización se queda corta:
- Fotos de móvil en ángulo: la distorsión confunde a los modelos de layout. Pide al usuario que escanee plano o use una app de doc-scanner.
- Faxes: el rango dinámico es brutal. Re-imprime y re-escanea si puedes.
- Etiquetas manuscritas: raras en formularios modernos pero presentes en formularios oficiales antiguos. Etiquetado manual inevitable.
- Formularios con símbolos no estándar: notación tipo ajedrez, ecuaciones, códigos institucionales propios. Necesitan entrenamiento custom, no OCR estándar.
- Layouts densos a varias columnas sin separación de espacios: los modelos de layout se atascan. Requiere ajustes.
El 90 % restante de los formularios reales funciona limpio. Conocer los modos de fallo evita prometer de más en una demo.
Consideraciones multilingües
Para equipos que manejan formularios no ingleses (la mayoría de nuestros lectores; mira nuestros flujos de siniestros, licitaciones públicas y dossier de visado), el idioma afecta al paso de OCR:
- Escrituras latinas (inglés, español, francés, alemán, portugués): cubiertas por todo motor OCR moderno.
- Escrituras RTL (árabe, hebreo): requieren motores OCR entrenados en layouts RTL. El orden de palabras y la dirección del campo cambian.
- Asia oriental (chino, japonés, coreano): requiere motores con datos de entrenamiento adecuados y un DPI más alto.
- Formularios con escrituras mixtas: muy comunes en visados (instrucciones en inglés + nombre en árabe). Motores que cubren ambas en una pasada ahorran un paso.
Las etiquetas de campo en el idioma fuente necesitan mapeo semántico a tus campos de perfil. Un campo Nationalité debe mapearse a Nacionalidad. El mapeo semántico moderno lo gestiona transparente; las herramientas antiguas exigían un diccionario de traducción.
El paso de exportación del que nadie habla
Un PDF correctamente relleno que se ve mal en el lector del receptor es funcionalmente un envío fallido. Tras rellenar y aplanar, valida en:
- Adobe Acrobat (el renderizador canónico de referencia)
- macOS Preview (motor distinto, saca a la luz problemas de fuentes)
- Visor PDF de Chrome (mínimo común para embajadas y agencias)
- Driver de impresora (algunas firmas solo se ven correctamente al imprimir)
Si la salida se renderiza limpia en los cuatro, tienes un PDF de calidad de envío. Si no, arregla el problema antes de mandar. Nunca asumas que la parte receptora usará el mismo lector que tú.
Árbol de decisión práctico
Cuando llega un nuevo PDF, el árbol es:
- ¿Es AcroForm? → Lee los campos directamente. Rellena. Aplana. Listo.
- ¿Es XFA? → Renderiza a imagen. Trata como PDF plano.
- ¿Es híbrido? → Lee el lado AcroForm. Rellena. Aplana. Listo.
- ¿Es plano o escaneado? → OCR + detección de layout. Mapea los campos detectados. Superpón valores. Aplana.
Una herramienta moderna ejecuta este árbol automáticamente. Tú subes, ella decide qué tipo de PDF es y enruta al pipeline correcto. Para el usuario es un único flujo.
Lectura relacionada
- La guía definitiva de autorrelleno con IA 2026: cómo encajan las piezas en un flujo de extremo a extremo.
- Flujo de partes de siniestro: los mismos cimientos técnicos en una vertical concreta.
- Relleno de formularios públicos: licitaciones y permisos: mismos cimientos en compras públicas.
- FillWizard vs Adobe Acrobat vs DocuSign: comparación directa de cómo tres herramientas conocidas manejan la división AcroForm/plano.
Qué hacer esta semana
Si tu equipo maneja una mezcla de AcroForm y PDF planos y solo automatiza una mitad, estás dejando el 50 % del ahorro encima de la mesa. Elige tres PDF planos de tu carga real, pásalos por una herramienta moderna con detección por visión y mide la salida. La diferencia entre "maneja PDF planos mal" y "maneja PDF planos bien" es exactamente la diferencia entre las herramientas de ayer y las de hoy.
Lista de verificación
- Identifica si cada PDF entrante es AcroForm, XFA, híbrido o plano/escaneado.
- Para AcroForms: lee nombres, tipos y estructura de los campos directamente, sin OCR.
- Para PDF planos: ejecuta OCR con un modelo de layout que detecte cajas de campo.
- Usa mapeo semántico para proyectar valores del perfil sobre los campos detectados.
- Conserva las firmas originales superponiendo valores en lugar de recrear el documento.
- Exporta a un PDF aplanado que abra bien en cualquier lector.
- Verifica la salida en Acrobat, Preview y un driver de impresora antes de mandarla.
Artículos relacionados
 Multilingual Workflows
Multilingual WorkflowsFormularios en árabe con IA: nombres en doble grafía, fechas Hijri y RTL que funciona de verdad
La mayoría de herramientas traducen la etiqueta y se quedan ahí. El trabajo real con formularios en árabe pide doble grafía, fechas Hijri y una capa de revisión que fluya del lado correcto.
9 min de lecturaLeer más Flujos de visa
Flujos de visaCómo la IA llena el formulario DS-160 en 4 minutos (y lo que no puede hacer)
El DS-160 toma 90 minutos la primera vez y 60 la segunda. La IA llena casi todo en cuatro minutos. La entrevista sigue siendo cosa tuya y del oficial consular.
8 min de lecturaLeer más Workflows fiscales
Workflows fiscalesDeclaración de la renta alemana con IA: guía práctica de Elster, Anlage N, KAP y S
Elster es obligatorio para casi todo, pero su interfaz es dura. Así funcionan Anlage N, KAP y S en la práctica, y así los rellena la IA con tus recibos y nóminas antes de presentar por Elster.
8 min de lecturaLeer más