AcroForm vs. flaches PDF: jedes Formular 2026 ausfüllbar machen
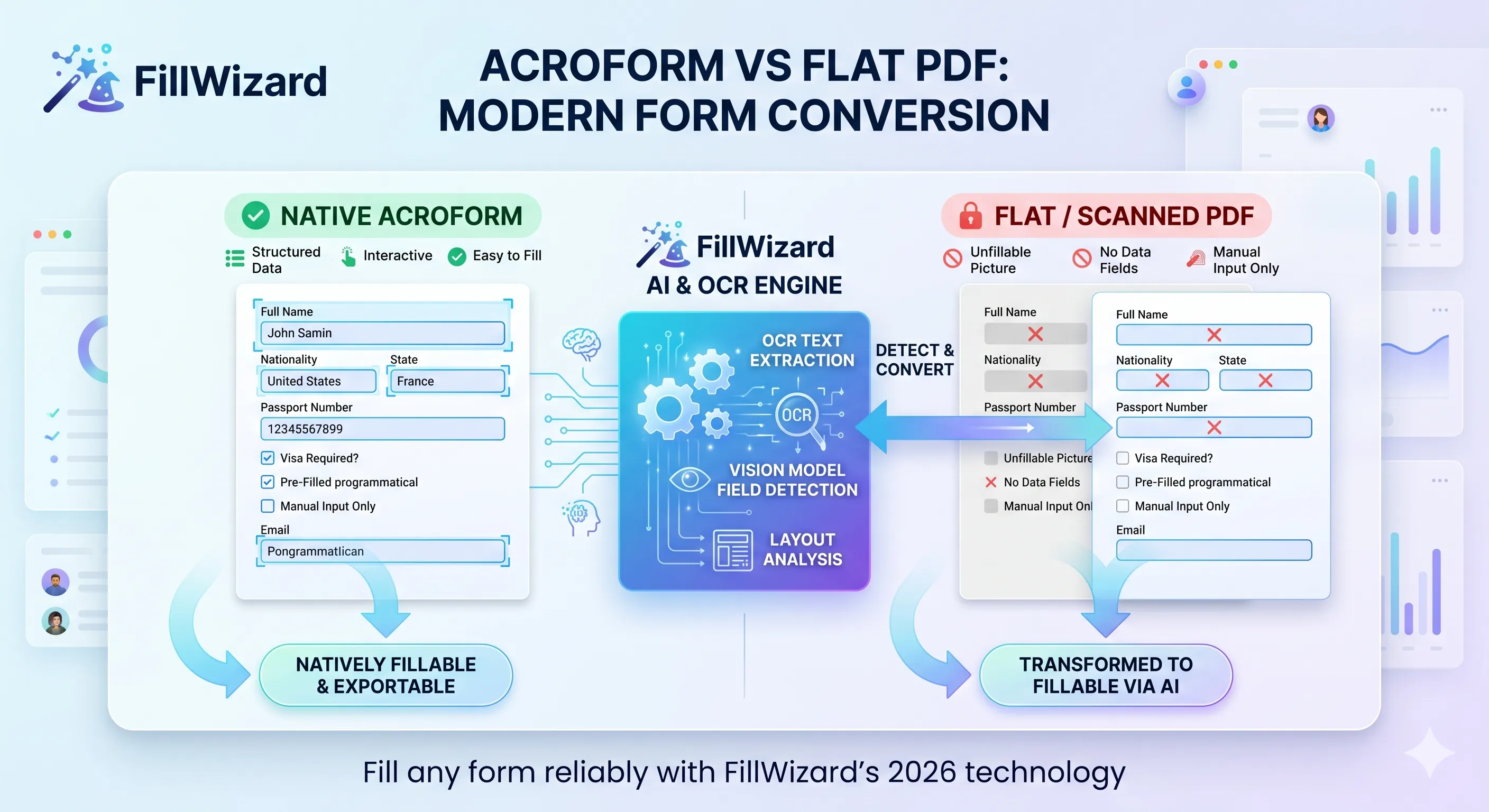
Wenn du je zwei optisch identische PDFs geöffnet hast und eines ließ sich tippen, das andere nicht, kennst du bereits die fundamentalste Spaltung im PDF-Universum. Beide sehen wie Formulare aus. Nur eines ist technisch eines. Das andere ist ein Bild eines Formulars.
Diesen Unterschied zu kennen, ist die Grundlage jedes modernen PDF-Autoausfüll-Workflows. Tools, die beides gleich behandeln, liefern kaputte Ergebnisse. Tools, die den Unterschied erkennen, befüllen beides zuverlässig. Dieser Artikel zeigt, was unter der Haube passiert, warum manche PDFs sich gegen Automatisierung wehren und wie 2026er-Tooling die Lücke schließt.
Es ist der technischste Beitrag der Reihe, aber du musst kein Engineer sein. Wenn du je <input> in HTML geschrieben hast, sind die Begriffe vertraut.
Die vier PDF-Arten, die wie Formulare aussehen
Die meisten denken bei "ausfüllbarem PDF" an eine Kategorie. Tatsächlich gibt es vier:
1. AcroForm
Eingeführt in PDF 1.2 (1996), ist AcroForm die dominante Technologie für ausfüllbare Formulare. Das PDF bettet Feldobjekte ein (/Annot-Einträge mit Subtype /Widget plus ein /AcroForm-Wörterbuch auf Dokumentebene). Jedes Feld hat:
- Einen Namen (z. B.
passport_number) - Einen Typ (Text, Button/Checkbox, Radio, Auswahl, Unterschrift)
- Eine Position auf der Seite (Rechteck im PDF-Koordinatenraum)
- Optionalen Default-Wert, Validierung und JavaScript-Aktionen
AcroForm-Felder sind abfragbar. Du öffnest das PDF programmatisch und kannst jedes Feld, seinen Namen, Typ und aktuellen Wert auflisten. Das meint "ausfüllbares PDF" im präzisen Sinn.
2. XFA (XML Forms Architecture)
Eingeführt in PDF 1.5 (2003), packt XFA eine XML-Formulardefinition in einen PDF-Container. Adobes Versuch, reichere Formularlogik (dynamische Felder, komplexe Validierung, bedingte Sektionen) ins PDF zu bringen. Funktioniert nur in Adobe Reader auf unterstützten Plattformen.
XFA wurde in PDF 2.0 (2017) abgekündigt. In älteren Behörden- und Unternehmensformularen ist es noch verbreitet. Wenn du je ein Steuerformular im Chrome-Viewer geöffnet hast und "Bitte in Adobe Reader öffnen" gesehen hast, war es XFA.
Für moderne Automatisierung behandelst du XFA am besten wie ein flaches PDF: rendern, OCR, befüllen. Direktes Manipulieren des XML ist brüchig und selten lohnenswert.
3. Hybrid (AcroForm + XFA)
Manche PDFs enthalten sowohl eine AcroForm- als auch eine XFA-Repräsentation desselben Formulars. Zur Rückwärtskompatibilität: Adobe Reader nutzt XFA, alles andere fällt auf AcroForm zurück. Hybride werden seltener, kommen aber in Finanz- und Behördenformularen vor 2018 vor.
Für Automatisierung: Lies die AcroForm-Seite, ignoriere die XFA-Seite, befülle die AcroForm-Felder, rechne beim Export flach.
4. Flach / gescannt
Ein flaches PDF hat keine ausfüllbare Struktur. Es ist eine Sequenz gerenderter Seiten (Text, Bilder, Vektorformen) ohne Feldkonzept. Die "Kästchen", die du siehst, sind visuelle Elemente, keine Daten.
Zwei Wege, wie flache PDFs entstehen:
- Original flach: Eine Designerin hat das Formular in InDesign gezeichnet, als PDF exportiert und nie AcroForm-Felder hinzugefügt. Die Kästchen sind Rechtecke. Die Label sind Text.
- Gescannt: Ein Papierformular wurde fotokopiert und als PDF gespeichert. Die ganze Seite ist im Wesentlichen ein Bild. Auch die Textlabel sind Pixel.
Das sind die PDFs, die "kein Tippen erlauben". Auch die, die ältere Tools nicht bewältigen, weil es nichts zum Abfragen gibt. Nur Pixel.
Warum die Unterscheidung operativ wichtig ist
Für Teams mit Tausenden von Formularen über mehrere Workflows hat die AcroForm/Flach-Spaltung echte Konsequenzen:
AcroForms sind 10-mal leichter zu automatisieren. Felder auflisten, mappen, Werte schreiben, flach rechnen. Der ganze Vorgang dauert Millisekunden.
Flache Formulare brauchen Erkennung. Du musst die Felder visuell finden (Bounding-Box-Detection), bevor du befüllen kannst. Hier verdienen moderne OCR und Vision-Modelle ihren Platz.
Gemischte Pakete sprengen naive Workflows. Ein echtes Visa-Paket, eine RFP-Antwort oder ein Schadenpaket enthält routinemäßig beides. Ein Workflow, der nur einen Typ kann, zwingt zu manueller Arbeit auf der anderen Hälfte.
Unterschriften unterscheiden sich stark. AcroForm-Signaturfelder lassen sich programmatisch befüllen. Flache Unterschriftslinien müssen überlagert werden. Verbockte Unterschriften machen Formulare ungültig.
Wie moderne Tools Felder in flachen PDFs erkennen
Wenn AcroForm-Felder direkt lesbar sind, passiert die spannende Engineering-Arbeit auf flachen PDFs. Die Erkennungs-Pipeline 2026 sieht so aus:
Schritt 1: Seite rendern
Das flache PDF wird in ein hochauflösendes Bild gerendert (typisch 300 DPI oder mehr). PDF.js, Poppler oder Ghostscript erledigen das zuverlässig.
Schritt 2: OCR
Text wird mit Positionen extrahiert. Moderne OCR-Engines (Tesseract 5, Google Document AI, Microsoft Azure Form Recognizer oder Open-Source-Modelle wie Donut und LayoutLM) liefern eine Liste von (Text, Bounding-Box)-Paaren.
Schritt 3: Layout-Analyse
Ein Layout-Modell findet strukturelle Regionen: Absätze, Tabellen, Überschriften, ausfüllbare Bereiche. Das Modell kennt das Aussehen eines Formulars: leere horizontale Linien neben Labeltext, Checkboxen als kleine leere Quadrate, Signaturlinien als horizontale Striche mit "Signature" darunter.
Schritt 4: Feldzuordnung
Jede ausfüllbare Region wird dem nächstgelegenen Label zugeordnet. "Passport number" neben einer horizontalen Linie heißt: die Linie ist ein Passnummernfeld. Hier glänzen Vision-Sprach-Modelle: Sie unterscheiden "Date of issue" von "Date of expiry" auch bei engem Layout.
Schritt 5: Typ-Klassifikation
Jedes erkannte Feld wird als Text, Checkbox, Unterschrift oder Datum klassifiziert. Das steuert das nachgelagerte Verhalten: Textfelder bekommen Profilwerte, Checkboxen werden gesetzt, Unterschriften werden für menschliches Handeln markiert.
Das Ergebnis dieser Pipeline ist eine Struktur, die praktisch identisch zu einer nativen AcroForm-Ausgabe aussieht. Ab da ist der Rest des Workflows derselbe.
Für eine Übersicht, wie das in eine komplette Engine passt, siehe unser definitiven KI-Autoausfüll-Leitfaden.
Warum alte Tools an flachen PDFs scheitern
Die vorhergehende Generation der PDF-Tools (Mitte der 2010er) versuchte das Flachproblem mit Template-Matching zu lösen. Der Workflow:
- Beispiel-PDF hochladen.
- Manuell auf jede Feldposition klicken, Box ziehen.
- Jede Box mit einem Feldnamen labeln.
- Template speichern.
Beim nächsten Mal mit demselben Layout projiziert das Tool das Template aufs neue PDF und füllt die Boxen.
Theoretisch funktioniert das. Praktisch zerbricht es aus drei Gründen:
- Template-Drift: schon kleine Änderungen (ein neues Logo, ein verschobener Disclaimer) bringen das Template aus dem Lot.
- Aufwand pro Formular: ein 40-Formular-Paket sind 40 Templates, je 5 bis 10 Minuten Setup.
- Kein semantischer Transfer: ein Template kennt Positionen, keine Bedeutung. Ein Feld "Last Name" bei einem Versicherer und "Surname" beim nächsten braucht zwei Templates.
Moderne Erkennungspipelines umgehen alle drei Probleme. Sie erkennen Felder jedes Mal frisch, labeln semantisch und brauchen kein Setup pro Formular.
Befüllen, ohne das Original zu zerstören
Sobald die Felder erkannt sind, muss das Befüllen chirurgisch sein. Zwei Fehlermodi:
Fehler 1: den Seiteninhalt direkt bearbeiten. Wenn du Profilwerte in den bestehenden Page-Stream platt drückst, gehen Dinge kaputt. Eingebettete Schriften verschwinden. Existierende Unterschriften werden ungültig. Metadaten werden verbogen. Manche PDF-Reader weigern sich zu rendern.
Fehler 2: Ein nicht flach gerechnetes PDF als Endergebnis speichern. Wenn du AcroForm-Felder befüllst und ohne Flachrechnung speicherst, kann der Empfänger Werte zurückbearbeiten. Für Einreichungen mit hohem Einsatz (Visum, Behörde, Recht) ist das untragbar.
Der richtige Weg in beiden Fällen:
- AcroForm-PDFs: Werte in bestehende Feldobjekte schreiben, beim Export flach rechnen. Resultat: ein sauberes, unveränderliches PDF, das in jedem Reader gleich aussieht.
- Flache PDFs: Seite rendern, Werte als Overlay auf die erkannten Feldpositionen legen, Ergebnis flach rechnen. Die existierenden Unterschriften (im Seiteninhalt) bleiben unangetastet. Die neuen Werte werden permanent Teil der Seite.
Ein gut gebautes Autoausfülltool wählt automatisch den richtigen Ansatz je nach Eingangstyp.
Wann OCR ehrlich nicht hilft
OCR hat Grenzen. Die ehrliche Liste der Fälle, in denen Automatisierung scheitert:
- Schräge Handyfotos: Trapez-Verzerrung verwirrt Layout-Modelle. Lass plan scannen oder eine Doc-Scanner-App nutzen.
- Faxe: brutaler Dynamikbereich. Wenn möglich, neu drucken und scannen.
- Handgeschriebene Label: selten in modernen Formularen, kommt in alten Behördenformularen vor. Manuelles Labeln unvermeidbar.
- Formulare mit ungewöhnlichen Symbolen: Schach-Notation, Mathe-Gleichungen, eigene Institutscodes. Brauchen eigenes Training, kein Standard-OCR.
- Mehrspaltige enge Layouts ohne Whitespace: Layout-Modelle ringen. Nachjustieren nötig.
Die übrigen 90 % der echten Formulare laufen sauber. Die Fehlermodi zu kennen verhindert Über-Versprechen in PoC-Demos.
Mehrsprachige Aspekte
Für Teams mit nicht englischen Formularen (die meisten unserer Leser; siehe unsere Workflows zu Schaden, Behördenausschreibung und Visa-Paket) beeinflusst die Sprache den OCR-Schritt:
- Lateinische Schriften (Englisch, Spanisch, Französisch, Deutsch, Portugiesisch): von jedem modernen OCR abgedeckt.
- RTL-Schriften (Arabisch, Hebräisch): brauchen OCR-Engines, die explizit auf RTL-Layouts trainiert sind. Wortreihenfolge und Feldrichtung kippen.
- Ostasiatische Schriften (Chinesisch, Japanisch, Koreanisch): brauchen passende Trainingsdaten und höhere DPI.
- Misch-Schriften: in Visa-Arbeit häufig (englische Anweisungen + arabisches Namensfeld). Engines, die beides in einem Lauf können, sparen einen Schritt.
Feldlabel in der Quellsprache brauchen semantisches Mapping auf deine Profilfelder. Ein Feld Nationalité muss auf Nationality mappen. Modernes Mapping erledigt das transparent; ältere Tools brauchten ein Übersetzungs-Wörterbuch.
Der Export-Schritt, über den niemand spricht
Ein korrekt befülltes PDF, das beim Empfänger schief rendert, ist faktisch eine fehlgeschlagene Einreichung. Nach Befüllen und Flachrechnen prüfe in:
- Adobe Acrobat (kanonischer Referenz-Renderer)
- macOS Preview (anderer Renderer, deckt Schriftprobleme auf)
- Chrome PDF-Viewer (kleinster gemeinsamer Nenner für Botschaften und Behörden)
- Druckertreiber (manche Unterschriften erscheinen nur im Druck korrekt)
Rendert die Ausgabe in allen vier sauber, ist es ein einreichungsfähiges PDF. Sonst behebe das Renderer-Problem vor dem Versand. Nimm nie an, dass der Empfänger denselben Reader nutzt wie du.
Praktischer Entscheidungsbaum
Wenn ein neues PDF kommt, sieht der Baum so aus:
- AcroForm? → Felder direkt lesen. Befüllen. Flach rechnen. Fertig.
- XFA? → Zu Bild rendern. Wie flaches PDF behandeln.
- Hybrid? → AcroForm-Seite lesen. Befüllen. Flach rechnen. Fertig.
- Flach oder gescannt? → OCR plus Layout-Erkennung. Erkannte Felder mappen. Werte überlagern. Flach rechnen.
Ein modernes Autoausfülltool fährt diesen Baum automatisch. Du lädst hoch, es entscheidet, welcher PDF-Typ vorliegt, und routet zur richtigen Pipeline. Aus Nutzersicht ein einziger Workflow.
Weiterlesen
- Der definitive KI-PDF-Autoausfüll-Leitfaden 2026: wie die Bausteine in einen End-to-End-Workflow passen.
- Schadenformular-Workflow: dieselben technischen Grundlagen in einer konkreten Branche.
- Behördenformulare ausfüllen: Ausschreibungen und Genehmigungen: dieselben Grundlagen, angewandt auf öffentliche Beschaffung.
- FillWizard vs. Adobe Acrobat vs. DocuSign: direkter Vergleich, wie drei populäre Tools die AcroForm/Flach-Spaltung handhaben.
Was diese Woche tun
Wenn dein Team eine Mischung aus AcroForm und flachen PDFs verarbeitet und nur eines davon automatisiert wird, lässt du 50 % der Zeitersparnis liegen. Wähle drei flache PDFs aus deiner echten Last, lass sie durch ein modernes Tool mit visionsbasierter Felderkennung laufen und miss das Ergebnis. Der Abstand zwischen "kommt mit flachen PDFs schlecht klar" und "kommt mit flachen PDFs gut klar" ist exakt der Abstand zwischen gestrigen und heutigen Tools.
Checkliste
- Stell für jedes eingehende PDF fest, ob es AcroForm, XFA, Hybrid oder flach/gescannt ist.
- Bei AcroForms: Feldnamen, Typen und Struktur direkt lesen, kein OCR nötig.
- Bei flachen PDFs: OCR mit einem Layout-Modell laufen lassen, das Feld-Boundingboxen erkennt.
- Profilwerte semantisch auf erkannte Felder projizieren.
- Bestehende Unterschriften erhalten, indem du Werte überlagerst statt das Dokument neu zu erzeugen.
- In ein flach gerechnetes PDF exportieren, das in jedem Reader sauber öffnet.
- Vor dem Versand das Ergebnis in Acrobat, Preview und einem Druckertreiber prüfen.
Verwandte Beiträge
 Multilingual Workflows
Multilingual WorkflowsArabische Formulare mit KI: Doppelschrift-Namen, Hijri-Daten und RTL-Layouts, die wirklich funktionieren
Die meisten Tools übersetzen das Label und hören auf. Echte Arbeit an arabischen Formularen braucht Doppelschrift-Namen, Hijri-Daten und eine Prüfschicht, die in die richtige Richtung läuft.
9 Min. LesezeitWeiterlesen Visa-Workflows
Visa-WorkflowsWie KI das DS-160-Visumformular in 4 Minuten ausfüllt (und was sie nicht kann)
Das DS-160 dauert beim ersten Mal 90 Minuten, beim zweiten Mal 60. KI füllt fast alles in vier. Das Interview bleibt zwischen Ihnen und dem Konsularbeamten.
8 Min. LesezeitWeiterlesen Steuer-Workflows
Steuer-WorkflowsSteuererklärung mit KI: Praxisleitfaden zu Elster, Anlage N, KAP und S
Elster ist Pflicht, aber die Bedienung tut weh. So funktionieren Anlage N, KAP und S in der Praxis, und so füllt KI sie aus Belegen und Lohnsteuerbescheinigung vor, bevor du in Elster abgibst.
8 Min. LesezeitWeiterlesen